GLOBAL SYNTHETIC DATA SOFTWARE MARKET SIZE (2023 - 2030):
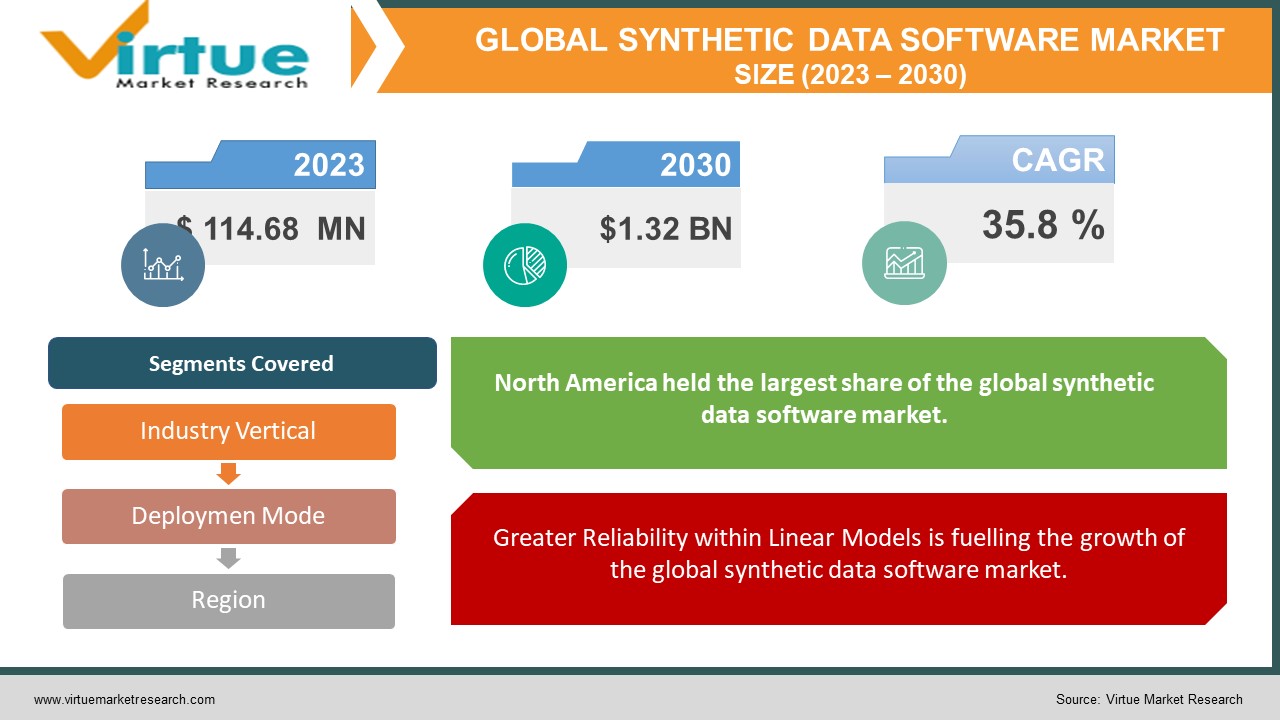
Global Synthetic Data Software Market is estimated to be worth USD 114.68 Million in 2023 and is projected to reach a value of USD 1.32 Billion by 2030, growing at a fast CAGR of 35.8% during the forecast period 2023-2030.
Synthetic data is artificial data created from original data and a model trained to replicate the traits and structure of the original data. A measure of the utility of the method and the model is the degree to which synthetic data is an accurate proxy for the original data. Various techniques, such as deep learning algorithms or decision trees, can be used to carry out the generation process, also referred to as synthesis. Based on the original data type, synthetic data can be classified into the following, the first type employs actual datasets, the second type employs knowledge gathered by analysts, and the third type is a mix of these two types. In the field of image recognition, Generative Adversarial Networks (GANs), which were recently introduced, are frequently utilized. Generally, they are made up of two neural networks training one another iteratively. The discriminator network tries to distinguish synthetic images produced by the generator from actual ones by comparing them to one another. To ensure that the generated synthetic data does not contain actual personal data, a privacy assurance assessment should be carried out, which evaluates the degree to which data subjects can be identified in the synthetic data and the amount of new data that would be revealed if successful identification is achieved.
Synthetic data is gaining popularity in the field of machine learning. It assists in training machine learning algorithms that need a lot of labeled training data, which can be expensive or have restrictions on the usage of data. Additionally, synthetic data can be used by manufacturers for software testing and quality control. Synthetic data can assist businesses and researchers in creating the data repositories necessary to train and even pre-train machine learning models.
Global Synthetic Data Software Market Drivers:
Greater Reliability within Linear Models is fuelling the growth of the global synthetic data software market.
Synthetic data of good quality represents original data with high accuracy. As a result, sensitive performance data can be substituted for synthetic data in non-production settings, including AI training, analytics, and software testing or development. To ensure customer privacy while making data-driven decisions, businesses employ synthetic data versions of patient experiences, customer databases, medical information, and transaction data. Banking, healthcare, insurance, and telecommunications are a few of t the industries he industries where synthetic data is employed as an industry-agnostic solution. Therefore, this factor propels the demand for synthetic data.
The growing adoption of cutting-edge technologies, including AI and ML, is another factor contributing to the growth of the global synthetic data software market.
Cutting-edge technologies, such as artificial intelligence (AI), machine learning (ML), and nanotechnologies, are being employed by businesses to improve operational effectiveness and create more revenue opportunities. Synthetic data will be an essential technology in handling data management challenges across domains of predictive analytics, privacy, security, and general data centricity. Today's AI-powered algorithms for generating synthetic data are capable of ingesting real data, learning its features, correlations, and patterns in great detail, and then generating infinite quantities of completely artificial, synthetic data that match the statistical qualities of the dataset that was initially ingested. The advanced, synthetic datasets are scalable, privacy and security compliant, and contain all of the original importance without the weight of sensitive information.
Global Synthetic Data Software Market Challenges:
The global synthetic data software market is encountering challenges, primarily in terms of complex output control and dependency on the data source for model quality. Comparing synthetic data to actual data or data that is human-annotated is the most effective method for ensuring that the output is accurate and consistent. Output control can be muddled, particularly with complex datasets. For this comparison, however, access to the original data is required. Moreover, there is a strong correlation between the quality of the synthetic data and the quality of the original data and the data generation model. Synthetic data may reflect the biases of the original data. Manipulating datasets to create fair synthetic datasets may result in inaccurate data. Thus, these challenges inhibit the growth of the global synthetic data software market.
Global Synthetic Data Software Market Opportunities:
The automotive industry's adoption of synthetic data software presents a lucrative opportunity in the global synthetic data software market. To train self-driving/autonomous vehicles, extensive amounts of data are required as the demand for them grows. Synthetic data software can offer a cost-effective and efficient way of producing enormous quantities of high-quality data that can be used to train these vehicles.
COVID-19 Impact on the Global Market:
The outbreak of the COVID-19 pandemic substantially impacted the global synthetic data software market. The implementation of strict lockdowns, travelling restrictions, and social distancing measures across several nations hindered many companies' manufacturing capacities and caused a shortage of skilled workforce. The pandemic caused disruptions in supply chains and distribution of goods and services, which reduced and delayed the output of synthetic datasets for training AI and ML models. These factors negatively impacted the growth of the global synthetic data software market. However, due to the travelling restrictions and lockdowns in almost every country, several organizations shifted to remote work and online operations, which increased the demand for synthetic data software to comply with data privacy and security. Moreover, the surge in demand for synthetic data software was witnessed in the healthcare industry as synthetic datasets are proven to be valuable in the testing and development of AI and ML algorithms in medical devices that are used to diagnose diseases and monitor and improve health conditions. These factors positively impacted the market's growth. Therefore, the global synthetic data software market experienced both challenges and opportunities during the difficult time of the COVID-19 pandemic.
Global Synthetic Data Software Market Recent Developments:
-
In March 2023, Gretel announced a collaboration with Google Cloud to accelerate the adoption of safer generative AI in businesses and harness the power of synthetic data. Gretel offers a synthetic data platform that makes it simple to generate anonymized, safe-to-share, and privacy-focused synthetic data for businesses blocked by data-sharing restrictions or a lack of data.
-
In March 2023, Synthesis AI, a pioneer in synthetic data technologies for computer vision, unveiled its enhanced capabilities to provide synthetic data for a variety of Automotive and Autonomous Vehicle (AV) use cases.
GLOBAL SYNTHETIC DATA SOFTWARE MARKET REPORT COVERAGE:
|
REPORT METRIC
|
DETAILS
|
|
Market Size Available
|
2022 - 2030
|
|
Base Year
|
2022
|
|
Forecast Period
|
2023 - 2030
|
|
CAGR
|
35.8 %
|
|
Segments Covered
|
By Deployment Mode, Industry Vertical and Region
|
|
Various Analyses Covered
|
Global, Regional & Country Level Analysis, Segment-Level Analysis, DROC, PESTLE Analysis, Porter’s Five Forces Analysis, Competitive Landscape, Analyst Overview on Investment Opportunities
|
|
Regional Scope
|
North America, Europe, APAC, Latin America, Middle East & Africa
|
|
Key Companies Profiled
|
Synthesis AI (United States), MOSTLY AI (Austria), IBM Corporation (United States)
Gretel (United States), Meta (United States)
NVIDIA Corporation (United States), CVEDIA (United Kingdom), Datagen (Israel), Kinetic Vision, Inc. (United States)
GenRocket (United States)
|
Global Synthetic Data Software Market Segmentation:
Global Synthetic Data Software Market Segmentation: By Deployment Mode
In 2022, the cloud-based segment held the highest market share. The growth can be attributed to the advantages that cloud-based deployment offers over on-premise regarding scalability, cost-effectiveness, accessibility, security, and integration with other cloud-based services.
Global Synthetic Data Software Market Segmentation: By Industry Vertical
-
BFSI
-
Transportation and Logistics
-
IT and Telecommunications
-
Government
-
Retail and E-commerce
-
Manufacturing
-
Healthcare and Life Sciences
-
Others
In 2022, the IT and telecommunications segment held the highest market share. The growth can be attributed to the increasing requirement for synthetic data software due to the extensive amount of data generated on a daily basis. Moreover, to cope with the evolving customer demands, many IT companies are adopting synthetic data software to assist in accelerating the testing and development of new products and services, which further propels the segment's growth.
Global Synthetic Data Software Market Segmentation: By Region
-
North America
-
Europe
-
Asia-Pacific
-
The Middle East & Africa
-
South America
In 2022, the region of North America held the largest share of the global synthetic data software market. The growth can be attributed to the growing usage of synthetic data software in various industries to enhance business operations and customer experience. The high amount of investments in research and development of synthetic data technologies by the United States government also propel the region's growth. In addition, the region is home to several major market players, including Gretel, Synthesis AI, IBM Corporation, NVIDIA Corporation, and GenRocket.
However, Asia Pacific is estimated to exhibit the highest growth owing to the growing adoption of cloud-based services and the increase in penetration of cutting-edge technologies, including AI and ML.
Global Synthetic Data Software Market Key Players:
-
Synthesis AI (United States)
-
MOSTLY AI (Austria)
-
IBM Corporation (United States)
-
Gretel (United States)
-
Meta (United States)
-
NVIDIA Corporation (United States)
-
CVEDIA (United Kingdom)
-
Datagen (Israel)
-
Kinetic Vision, Inc. (United States)
-
GenRocket (United States)






